
Good orange or bad orange? A low code machine learning model
The development of low-code or no-code applications is an increasingly valuable solution for both developers and individual or organizational users. At this moment, there wouldn't be the capacity to respond to the volume of ongoing process automation and digital transformation projects. So far, companies have successfully replaced emails and standalone spreadsheets with apps that ensure integrity, functionality, design, traceability, and secure data access.
The time has come to adopt the same approach in the development of machine learning and deep learning models, which are typically challenging to develop and operationalize. In this article, we will demonstrate how to train a predictive model capable of distinguishing between good and poor-quality oranges. Additionally, we'll develop a mobile application that uses this model through the camera to classify oranges displayed in a supermarket.
For the supermarket, the benefit of such a model is the rapid classification of fruit into different categories, whose prices can vary significantly. Consumers tend to value a "good orange" more than a "poor orange" based on visual appearance. If the model can perform this task, it will assist in merchandising, defining promotions, and reducing manual work.
The entire development will be done with minimal reliance on programming languages. For the model development, we'll use Lobe, and for the mobile application development, we'll use Power Apps.
Training the model
One of the most important aspects of developing machine learning models is that they learn from examples. Unlike what happens in traditional development, where logical rules are specified, such as "if this happens, then we do that", in machine learning models, we use algorithms that learn from training data (examples), which will serve so that the model is able to correctly predict when it is presented with new data that the model has not yet seen.
In our case, the training data is images of oranges. We will need to show a significant number of examples of each of the classes of "good orange" and "bad orange" in order for the model to learn and be able to generalize. We're going to use about 30 images from each of the two classes collected with a mobile phone camera.
In Lobe, we create a new project and start by uploading the images and manually assigning each one its own rating.
Here are some pictures of the good oranges:

And some of the bad ones:

Is it easy for a human to recognize the difference between one and the other? We don't know, it will depend on the experience and knowledge of each one. Just like a human, the more experience the model will be so much more effective and that will depend on the number of examples we show you, as well as the different perspectives you can get from an orange.
That's why we show a fair number of photos of good and bad oranges taken from different angles and perspectives.
Note that an orange has a relatively symmetrical image, which helps a lot in learning the model. But if we were trying to recognise emotions in a human face, for example, although it is also relatively symmetrical when looked at from the front, the same cannot be said if we look at it from the side, from below or from above. Therefore, it is necessary to show it to the model from all possible angles so that it learns.
Another interesting issue is that we don't always have a sufficient number of images to effectively train a model. A practical solution for leaders with this problem is to resort to "data augmentation", which very briefly consists of reusing the same image in the training data, but enlarging or reducing its size, changing its vertical or horizontal orientation, for example. This will teach the model to recognize the same image from different perspectives.
The model learns very easily how to handle the training data and recognizes 100% each of the classes:
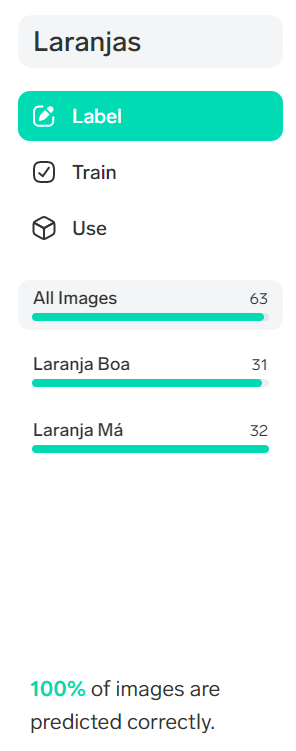
Perhaps the challenge was too easy for Lobe to handle so effectively! The question that arises at this point is how to test this model on data that you don't know yet?
Test the effectiveness of the model with new images
The app allows you to quickly test it in a variety of ways. We can simply drag images of new oranges into the app or even use the webcam and see how the model responds.
Let's look at the results on two new oranges:
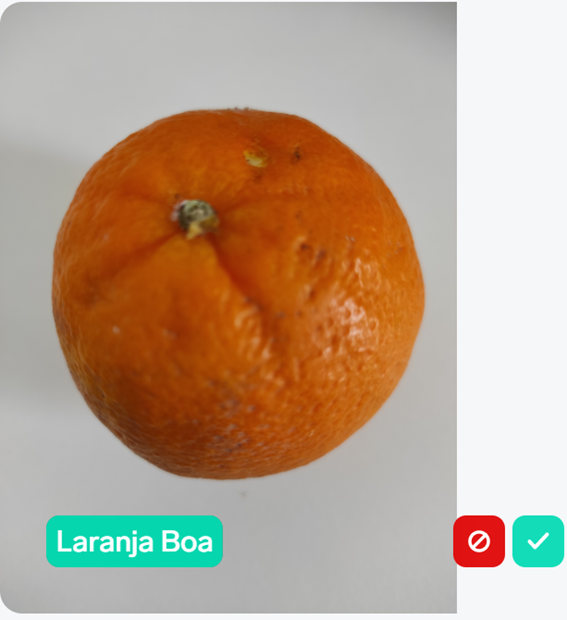
With the first one, the model gets it right, it's a good orange! We have the opportunity to give this feedback, indicating that everything went well the first time, and this image joins the images we used during training.
This helps to further improve the effectiveness of the model!
The second orange is a bit more challenging. On one side, it looks great, but when we see it on the other side, we have some doubts. Let's see what it looks like on the first side:

This orange looks really good and the model agrees! But if we see it from the opposite side, what will the classification look like?

On this side, it is already classified as bad! Perhaps the model has learned from the orange stains to classify it as bad and as good, when there are no stains. Maybe it was the brightness or the texture, it's a little hard to say, all we know is that there are no perfect models and even if a human looked at this orange from both sides they could have doubts about how to classify it. Different people would classify it in different ways...
The end result, considering this last orange as good, is as follows. 98% of the oranges were sorted correctly, which isn't bad at all!
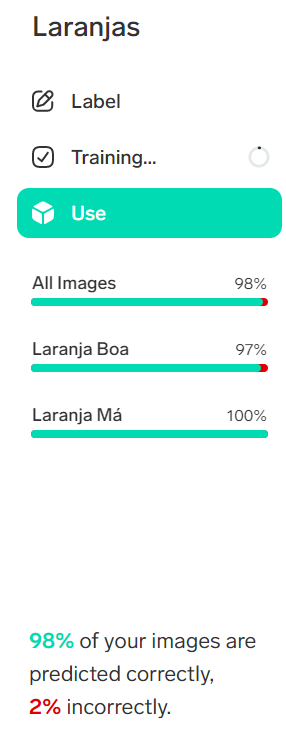
How to operationalize (consume) this model?
Of course, if we had to deal with thousands of oranges a day, it might not be practical to upload the images one by one to the app. To this end, Lobe has several solutions for implementing the models for various platforms.
One of the options, which easily integrates with Power Apps and Power Automate, is the one that allows you to consume the model in AI Builder:

Let's call it "Oranges Model" and export this model to one of the environments of the Power platform:
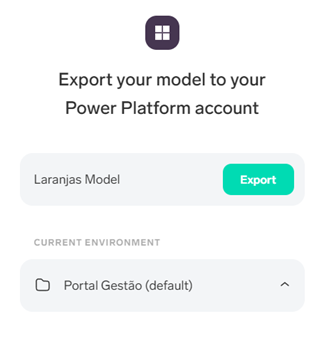
Within minutes, the model is available in AI Builder and we're ready to integrate it with Power Apps:

If you've ever developed predictive models using a pro-code solution, such as Python or R, you'll know how technical the deployment part is. In some cases, it is even more complex to implement the model than to develop it itself and that is why this integration with the Power platform is so welcome!
In the next article, we'll show you how to develop an app with Power Apps that uses this model. Stay tuned!
