- Imagem:
Termos estatísticos que você ainda não conhece, mas que podem alavancar o seu negócio
Um dicionário estatístico para quem não é da área: no artigo de hoje, vou traduzir alguns termos teóricos em casos práticos que estão a revolucionar o mercado coorporativo.

Em muitos projetos de análises de negócios, queremos encontrar “correlações” entre uma variável específica descrevendo um indivíduo e outras variáveis. Por exemplo, em histórico de dados podemos saber quais clientes deixaram a empresa após o vencimento de seus contratos. Podemos querer descobrir que outras variáveis se correlacionam com um cliente deixar a empresa no futuro próximo, através de um modelo de Churn, por exemplo. Encontrar tais correlações são os exemplos mais básicos de tarefas de classificação e regressão.
Desse modo, pretendo esclarecer 9 termos mais teóricos, porém voltados para aplicações reais, em situações comuns dentro do ambiente corporativo, que podem lhe ajudar a gerar insights valiosíssimos. Que tal pensarmos sobre esses assuntos?
1. Classificação e estimativa de probabilidade de classe tentam prever, para cada indivíduo de uma população, a que (pequeno) conjunto de classes este indivíduo pertence. Geralmente, as classes são mutuamente exclusivas. Um exemplo de pergunta de classificação seria: “Entre todos os clientes da minha empresa, quais são suscetíveis de responder a determinada oferta?” Neste exemplo, as duas classes poderiam ser chamadas: vai responder e não vai responder. Para uma tarefa de classificação, o processo de mineração de dados produz um modelo que, dado um novo indivíduo, determina a que classe o indivíduo pertence.

Uma tarefa intimamente relacionada é pontuação ou estimativa de probabilidade de classe. O modelo de pontuação aplicado a um indivíduo produz, em vez de uma previsão de classe, uma pontuação que representa a probabilidade (ou outra quantificação de probabilidade) de que o indivíduo pertença a cada classe. Em nosso cenário de resposta ao cliente, um modelo de pontuação seria capaz de avaliar cada cliente e produzir uma pontuação da probabilidade de cada um responder à oferta. Classificação e pontuação estão intimamente relacionadas; um modelo que pode fazer um, normalmente pode ser modificado para fazer o outro.
2. Regressão (“estimativa de valor”) tenta estimar ou prever, para cada indivíduo, o valor numérico de alguma variável. Um exemplo de pergunta de regressão seria: “Quanto determinado cliente usará do serviço?” A propriedade (variável) a ser prevista aqui é o uso do serviço, e um modelo poderia ser gerado analisando outros indivíduos semelhantes na população e seus históricos de uso. Um procedimento de regressão produz um modelo que, dado um indivíduo, calcula o valor da variável específica para aquele indivíduo. A regressão está relacionada com a classificação, porém, as duas são diferentes. Informalmente, a classificação prevê se alguma coisa vai acontecer, enquanto a regressão prevê quanto de alguma coisa vai acontecer.


3. Combinação por similaridade tenta identificar indivíduos semelhantes com base nos dados conhecidos sobre eles. A combinação de similaridade pode ser usada diretamente para encontrar entidades semelhantes. Por exemplo, a IBM está interessada em encontrar empresas semelhantes aos seus melhores clientes comerciais, a fim de concentrar sua força de vendas nas melhores oportunidades. Eles usam a combinação por similaridade com base dos dados “firmográficos”, que descrevem as características das empresas. A combinação por similaridade é a base de um dos métodos mais populares para se fazer recomendações de produtos (encontrar pessoas semelhantes a você, em termos de produtos que tenham gostado ou comprado). Medidas de similaridade são a base de determinadas soluções ou outras tarefas de mineração de dados, como classificação, regressão e agrupamento.

4. Agrupamento tenta reunir indivíduos de uma população por meio de sua similaridade, mas não é motivado por nenhum propósito específico. Um exemplo de pergunta de agrupamento seria: “Nossos clientes formam grupos naturais ou segmentos?” O agrupamento é útil na exploração preliminar de domínio para ver quais grupos naturais existem, pois, esses grupos, por sua vez, podem sugerir outras tarefas ou abordagens de mineração de dados. O agrupamento também é utilizado como entrada para processos de tomada de decisão com foco em questões como: quais produtos devemos oferecer ou desenvolver? Como nossas equipes de atendimento ao cliente (ou equipas de vendas) devem ser estruturadas?
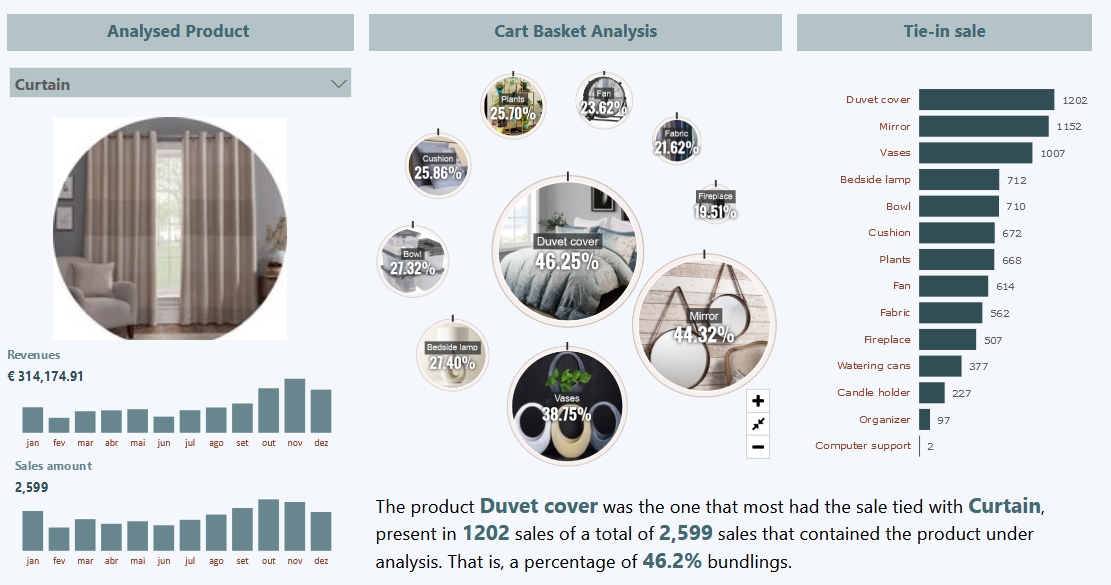
5. Agrupamento de coocorrência (também conhecido como mineração de conjunto de itens frequentes, descoberta da regra de associação e análise de portfólio de ações) tenta encontrar associações entre entidades com base em transações que as envolvem. Um exemplo de pergunta de coocorrência seria: Quais itens são comumente comprados juntos? Enquanto o agrupamento analisa as semelhanças entre os objetos com base em seus atributos, o agrupamento de coocorrência considera a similaridade dos objetos com base em suas aparições conjuntas nas transações. Por exemplo, analisar os registos de compras de um supermercado pode revelar que carne moída é comprada junto com molho de pimenta com muito mais frequência do que se poderia esperar. Decidir como agir de acordo com essa descoberta pode exigir um pouco de criatividade, mas pode sugerir uma promoção especial, a exibição do produto ou uma oferta combinada.
Coocorrência de produtos em compras é um tipo comum de agrupamento conhecido como análise de portfólio de ações. Alguns sistemas de recomendação também realizam um tipo de agrupamento por afinidade encontrando, por exemplo, pares de livros que são frequentemente comprados pelas mesmas pessoas (“pessoas que compraram X também compraram Y”). O resultado do agrupamento por coocorrência é uma descrição dos itens que ocorrem juntos. Essas descrições geralmente incluem estatísticas sobre a frequência da coocorrência e uma estimativa do quanto ela é surpreendente.
6. Perfilhamento (também conhecido como descrição de comportamento) tenta caracterizar o comportamento típico de um indivíduo, grupo ou população. Um exemplo de pergunta de perfilhamento seria: “Qual é o uso típico de telemóvel nesse segmento de cliente?” O comportamento pode não ter uma descrição simples; traçar o perfil do uso do telemóvel pode exigir uma descrição complexa das médias durante a noite e finais de semana, uso internacional, tarifas de roaming, conteúdos de texto e assim por diante. O comportamento pode ser descrito de forma geral, para uma população inteira, ou ao nível de pequenos grupos ou mesmo indivíduos.
O perfilhamento muitas vezes é usado para estabelecer normas de comportamento para aplicações de deteção de anomalias como deteção de fraudes e monitoramento de invasões a sistemas de computador (como alguém invadindo sua conta no iTunes). Por exemplo, se sabemos que tipo de compras uma pessoa normalmente faz no cartão de crédito, podemos determinar se uma nova cobrança no cartão se encaixa no perfil ou não. Podemos usar o grau de disparidade como uma pontuação suspeita e emitir um alarme, se for muito elevada.
7. Previsão de vínculotenta prever ligações entre itens de dados, geralmente sugerindo que um vínculo deveria existir e, possivelmente, também estimando a força do vínculo. A previsão de vínculo é comum em sistemas de redes sociais: “Como você e João partilham 10 amigos, talvez você gostaria de ser amigo de Manuel?” A previsão de vínculo também pode estimar a força de um vínculo. Por exemplo, para recomendar filmes para clientes pode-se imaginar um gráfico entre os clientes e os filmes que eles já assistiram ou classificaram. No gráfico, buscamos vínculos que não existem entre os clientes e os filmes, mas que prevemos que deveriam existir e deveriam ser fortes. Esses vínculos formam a base das recomendações.
Exemplo atuais de sistemas de recomendação: Netflix, Amazon, Spotify,…
8. Redução de dados (redução de dimensionalidade) tenta pegar um grande conjunto de dados e substituí-lo por um conjunto menor que contém grande parte das informações importantes do conjunto maior. Pode ser mais fácil de lidar com ou processar um conjunto menor de dados. Além do mais, ele pode revelar melhor as informações. Por exemplo, um enorme conjunto de dados sobre preferências de filmes dos consumidores pode ser reduzido a um conjunto de dados muito menor revelando os gostos do consumidor mais evidentes na visualização de dados (por exemplo, preferências de gênero dos espectadores). A redução de dados geralmente envolve perda de informação ou mesmo algum tipo de agregação. O importante é o equilíbrio para uma melhor compreensão.
9. Modelagem causal tenta nos ajudar a compreender que acontecimentos ou ações realmente influenciam outras pessoas. Por exemplo, considere que usamos modelagem preditiva para direcionar anúncios para consumidores e observamos que, na verdade, os consumidores alvo compram em uma taxa mais elevada após terem sido alvo. Isso aconteceu porque os anúncios influenciaram os consumidores a comprar? Ou os modelos preditivos simplesmente fizeram um bom trabalho ao identificar os consumidores que teriam comprado de qualquer forma?
Técnicas de modelagem causal incluem aquelas que envolvem um investimento substancial em dados, como experimentos randomizados controlados (por exemplo, os chamados “testes A/B”), bem como métodos sofisticados para obter conclusões causais a partir de dados observacionais. Ambos os métodos experimentais e observacionais para modelagem causal geralmente podem ser visualizados como análises “contra factuais”: eles tentam compreender qual seria a diferença entre as situações — exclusivas entre si — onde o evento “tratamento” (por exemplo, mostrar um anúncio para um indivíduo em particular) aconteceria e não aconteceria.
Em todos os casos, um cuidadoso cientista de dados sempre deve incluir, com uma conclusão causal, os pressupostos exatos que devem ser feitos para que a conclusão causal se mantenha (essas suposições sempre existem — sempre pergunte). Ao aplicar a modelagem causal, uma empresa precisa ponderar o dilema de aumentar os investimentos para reduzir as suposições formuladas versus decidir que as conclusões são suficientemente boas, dadas as suposições. Mesmo no experimento mais cuidadoso, randomizado e controlado, são feitas suposições que poderiam invalidar as conclusões causais. A descoberta do “efeito placebo” na medicina ilustra uma situação notória em que uma suposição foi ignorada em uma experimentação randomizada cuidadosamente projetada.
O que acharam? Que tal investirmos em inteligência para o nosso negócio?
Espero vocês no próximo artigo.
Isa