
Laranja boa ou laranja má? Um modelo Machine Learning Low Code
O desenvolvimento de aplicações low-code ou no-code é uma solução cada vez mais valiosa, quer para desenvolvedores quer para utilizadores individuais ou organizacionais. Não existiria neste momento capacidade de resposta ao volume de projetos de desenvolvimento de automação de processos e de transformação digital em curso. Até aqui, as empresas têm substituído com sucesso os e-mails e as folhas de cálculo avulso por apps que asseguram integridade, funcionalidade, design, rastreabilidade e segurança no acesso aos dados.
Chegou o momento de adotar a mesma abordagem no desenvolvimento de modelos de machine learning e deep learning, tipicamente difíceis de desenvolver e de operacionalizar.
Neste artigo, vamos demonstrar como treinar um modelo preditivo que seja capaz de distinguir laranjas de boa qualidade de laranjas de má qualidade. E como desenvolver uma aplicação móvel que através da câmara consiga utilizar esse modelo e classificar as laranjas expostas num supermercado.
Para o supermercado, o benefício de um modelo deste género é a rápida classificação de peças de fruta em diferentes categorias, cujos preços podem variar significativamente. O consumidor irá valorizar mais a “laranja boa” do que a “laranja má” em função do seu aspeto visual, pelo que se o modelo for capaz de fazer esse trabalho por nós, isso ajudará no merchandising, na definição de promoções e no trabalho manual.
Todo o desenvolvimento será feito praticamente sem recorrer a linguagens de programação. Para o desenvolvimento do modelo vamos utilizar o Lobe e para o desenvolvimento da aplicação móvel, o Power Apps.
Treinar o modelo
Um dos aspetos mais importantes no desenvolvimento de modelos de machine learning, é que eles aprendem com exemplos. Ao contrário do que acontece no desenvolvimento tradicional, em que se especificam regras lógicas, do tipo “se isto acontece, então fazemos aquilo”, nos modelos de machine learning, usamos algoritmos que aprendem com dados de treino (exemplos), que servirão para que o modelo seja capaz de prever corretamente quando lhe forem apresentados dados novos que o modelo ainda não viu.
No nosso caso, os dados de treino são imagens de laranjas. Teremos de mostrar um número significativo de exemplos de cada uma das classes de “laranja boa” e “laranja má” para que o modelo aprenda e seja capaz de generalizar. Vamos usar cerca de 30 imagens de cada uma das duas classes recolhidas com a câmara de um telemóvel.
No Lobe, criamos um novo projeto e começamos por carregar as imagens e manualmente atribuir a cada uma a respetiva classificação.
Aqui estão algumas imagens das laranjas boas:

E algumas das laranjas más:

Será fácil para um humano reconhecer a diferença entre uma e outra? Não sabemos, dependerá da experiência e conhecimento de cada um. Tal como um humano, o modelo será tão mais eficaz quanto mais experiência tiver e isso dependerá do número de exemplos que lhe mostrarmos, assim como das diferentes perspetivas que se poderão retirar de uma laranja.
Por isso, mostramos um número razoável de fotografias de laranjas boas e más retiradas de diversos ângulos e perspetivas.
Note que uma laranja tem uma imagem relativamente simétrica, o que ajuda bastante na aprendizagem do modelo. Mas, se estivéssemos a tentar reconhecer emoções num rosto humano, por exemplo, apesar de também ser relativamente simétrico quando olhado de frente, o mesmo não se poderá dizer se o olharmos de lado, de baixo ou de cima. Por isso, é necessário mostrá-lo ao modelo de todos os ângulos possíveis para que ele aprenda.
Outra questão interessante é que nem sempre dispomos de um número suficiente de imagens para treinar eficazmente um modelo. Uma solução prática para líder com esse problema é recorrer a “data augmentation”, que muito resumidamente consiste em reutilizar a mesma imagem nos dados de treino, mas ampliando-a ou reduzindo o seu tamanho, alterando a sua orientação vertical ou horizontal, por exemplo. Isto ensinará o modelo a reconhecer a mesma imagem de diversas perspetivas.
O modelo aprende muito facilmente a lidar com os dados de treino e reconhece 100% cada uma das classes:
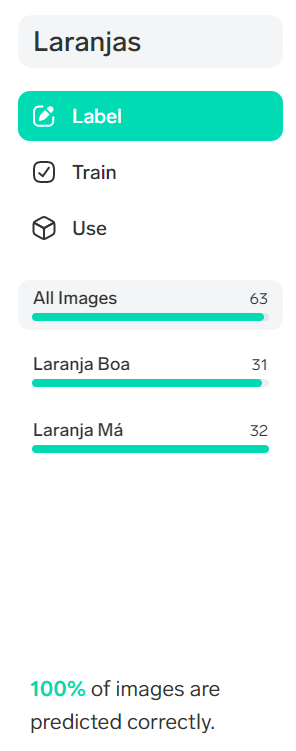
Talvez o desafio tenha sido demasiado fácil para o Lobe lidar com ele com tanta eficácia! A questão que se coloca neste momento é como testar este modelo em dados que ainda não conhece?
Testar a eficácia do modelo com novas imagens
A aplicação permite testá-lo rapidamente de diversas formas. Podemos simplesmente arrastar imagens de novas laranjas para a aplicação ou mesmo utilizar a webcam e ver como o modelo responde.
Vejamos os resultados em duas novas laranjas:
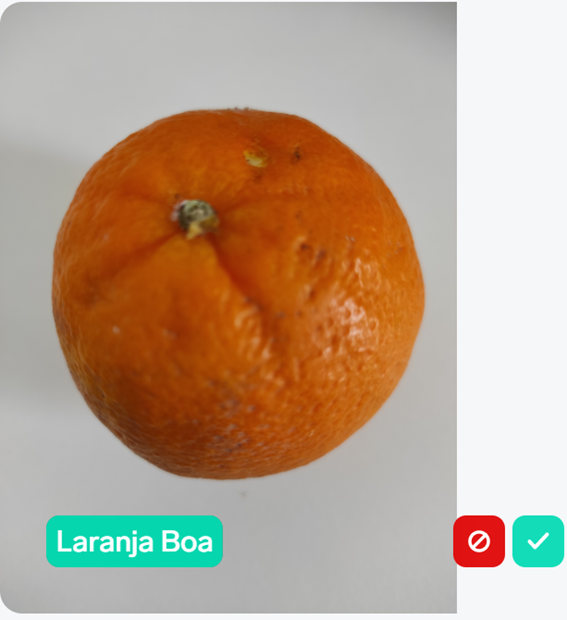
Com a primeira, o modelo acerta, trata-se de uma laranja boa! Temos a oportunidade de dar este feedback, indicando que tudo correu bem à primeira, e esta imagem junta-se às imagens que utilizamos durante o treino.
Isto ajuda a melhorar ainda mais a eficácia do modelo!
A segunda laranja é um pouco mais desafiadora. De um lado, parece ótima, mas quando a vemos do outro lado, temos algumas dúvidas. Vejamos como parece do primeiro lado:

Esta laranja parece mesmo boa e o modelo concorda! Mas se a virmos do lado oposto, como será a classificação?

Deste lado, já é classificada como má! Talvez o modelo tenha aprendido com as manchas da laranja a classificá-la como má e como boa, quando não existem manchas. Talvez tenha sido o brilho ou a textura, é um pouco difícil de dizer, tudo o que sabemos é que não existem modelos perfeitos e mesmo que um ser humano olhasse para esta laranja de ambos os lados poderia ter dúvidas sobre como classificá-la. Pessoas diferentes classificá-la-iam de formas diferentes…
O resultado final, considerando esta última laranja como boa, é o seguinte. 98% das laranjas foram classificadas corretamente, o que não é nada mau!
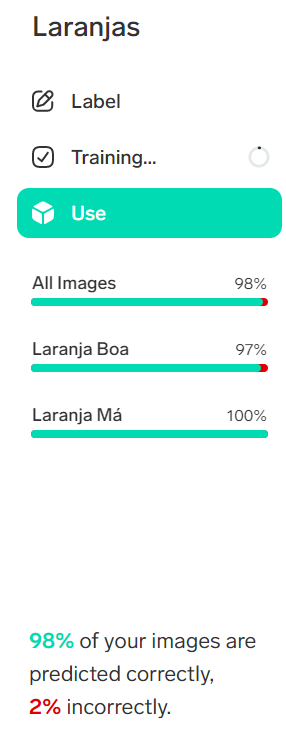
Como operacionalizar (consumir) este modelo?
Claro que se tivéssemos de lidar com milhares de laranjas por dia, talvez não fosse prático carregar as imagens uma a uma para a aplicação. Para isso, o Lobe dispõe de diversas soluções de implementação dos modelos para várias plataformas.
Uma das opções, que se integra facilmente com o Power Apps e com o Power Automate é a que permite consumir o modelo no AI Builder:

Vamos chamar-lhe “Laranjas Model” e exportar este modelo para um dos ambientes da plataforma Power:
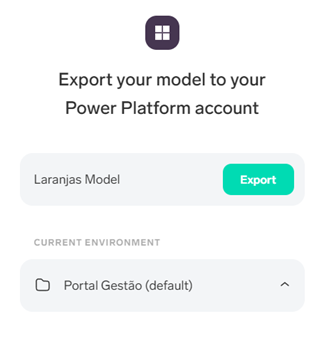
Em poucos minutos, o modelo fica disponível no AI Builder e estamos prontos a integrá-lo com o Power Apps:

Se já desenvolveu modelos preditivos utilizando alguma solução “high code”, com Python ou R, saberá quão técnica é a parte do deployment. Em alguns casos, é mesmo mais complexa a implementação do modelo do que o seu próprio desenvolvimento e é por isso que esta integração com a plataforma Power é tão bem-vinda!
No próximo artigo, mostraremos como desenvolver uma app com o Power Apps que utiliza este modelo. Stay tuned!
