
Porque é que a minha empresa se deve preocupar com Governança e Manutenção dos Dados?
Recentemente, durante uma formação online de Power BI, aqui na Portal Gestão, um aluno fez me essa pergunta. E achei-a tão importante, que decidi escrever sobre este assunto, para que outras pessoas também entendam a dimensão deste assunto.
Que os dados são o novo petróleo do século, já todos sabemos. Nunca tivemos tantos dados à nossa disposição para tratar, analisar e auxiliar na tomada de decisão. No entanto, com isso vem inúmeros desafios e preocupações, como por exemplo, a gestão dos dados, a segurança, privacidade, extração e higienização das informações, dentre muitas outras.

Com isso, administração e governança dos dados é o tipo de assunto que tem estado cada vez mais em voga.
Mas Isa, porque é que nos deveríamos preocupar com a governança dos dados? Como posso montar uma arquitetura correta no Power BI? Como funcionam as questões de administração e segurança do Power BI?
Antes de começar a responder tais perguntas, vamos dar um passo atrás e enxergar qual é o cenário atual de muitas empresas.
Antes de implementar o Power BI, é comum vermos:
- Uso extensivo de muitos ficheiros Excel pelos analistas.
Não é que o Excel seja mau, não é isso. O Excel tem muito valor, é uma ferramenta extraordinária e muita gente usa. Afinal, já está no mercado há mais de 3 décadas. Porém, para conseguirmos manter uma governança adequada de relatórios e gerir tudo isto, não é trivial.
- Muitas tarefas repetitivas e demoradas
Isto é o tipo de coisa que costumo chamar de “aspirador de energias”, pois os analistas não conseguem focar naquilo que eles são bons: que é analisar os dados. Com isso, passam a fazer tarefas repetitivas ao longo de dias ou mesmo semanas, que consomem imenso tempo. E acabam por se sentir improdutivos.
Por exemplo, caso queira fazer uma análise nova no relatório do Excel, e ao virar o mês, terá que repetir tudo de novo, se não souber utilizar VBA e Macros.
- Demora no processamento das informações
O Excel não é tão performático, em termos de processamento de dados quanto o Power BI. Arquivos muito grandes, deixam-no pesado (armazenamento de cache)
- Alta dependência da TI para extração dos dados
- Partilha das informações por e-mail ou apresentação de Power Point (relatório_final_atualizado_new_v1.8)
Isto é extremamente perigoso, além de gerar dúvidas para saber qual a versão, de facto, é a correta. O que dificulta a chegar em um consenso nos números.
Daí surgiu o Power BI e seus problemas acabaram!
Mas será mesmo? Será que ao usar o Power BI eu não vou ter mais estesproblemas? A resposta é não. Sabemos que não. E por isso nos devemos preocupar com o futuro, com questões de manutenção dos dados e performance.
Implementar uma solução de Power BI é relativamente simples. Difícil é mantê-la e fazer crescer de forma organizada e sustentável.
Uma coisa que devemos evitar ao máximo é a partilha de arquivos pbix por e-mail. Please! Não façam isso.
Self-Service BI não significa fazer as coisas de qualquer jeito, do jeito que quiser. Atenção a isso.
É importantíssimo a presença da equipa da TI no quesito manutenção e governança. Vejo muita gente a aprender Power BI e começar a criar relatórios “infinitamente”. Atenção, nada contra isso. O problema é que muitas das vezes, são partilhadas as mesmas bases de dados diversas vezes. Ou seja, um problema de duplicação das mesmas informações.
Automatizar tarefas repetitivas que antes eram feitas de forma manual no Excel, por exemplo, foi apenas o primeiro passo para estabelecer uma cultura de governança de dados na sua empresa.
Esse problema fica muito claro quando precisamos realizar a manutenção e a governança dos dados. Pois teremos de realizar as transformações em todos os ficheiros. Ou seja:
- Trabalho repetitivo: as mesmas transformações de dados a serem realizadas em diferentes arquivos pbix
- Falta de padronização nos processos: diferentes pessoas realizam ETL de modos diferentes
Resultado final: criação de vários silos de dados totalmente “despadronizados”.

Porque é que os silos de dados são um problema?
Os silos de dados são um problema por três motivos principais:
- Incapacidade de obter uma visão abrangente dos dados: Se os seus dados estiverem em silos, as conexões relevantes entre os dados em silos podem ser facilmente perdidas. Suponha, por exemplo, que a equipa de marketing tenha dados excelentes sobre quais campanhas de marketing atraíram muita atenção em uma determinada geografia, enquanto a equipe de vendas tem informações sobre vendas nessa mesma geografia. E se você pudesse reunir essas informações? Imagine como seria mais clara a relação entre campanhas de marketing e vendas.
- Recursos desperdiçados: Considere o que acontece se tiver um banco de dados com informações do cliente para a equipe de marketing e outro separado para a equipe de vendas. Muitos dados são duplicados entre esses departamentos. Custa dinheiro armazenar todos esses dados e, quanto mais dados uma empresa armazena, menos ela pode gastar em outros requisitos. Também se perde muito tempo procurando, corrigindo e corroborando informações que poderiam (e deveriam) estar prontamente acessíveis.
- Dados inconsistentes: Em silos de dados, é comum armazenar as mesmas informações em locais diferentes. Quando isso acontece, há uma grande chance de introduzir inconsistências de dados. Pode atualizar o endereço de um cliente em um lugar e não em outro. Ou pode introduzir um erro de digitação num conjunto de informações. Quando os dados estão num lugar, tem uma chance muito melhor de manter as informações corretas.
Desafios em lidar com dados isolados
Embora muitas empresas reconheçam que os silos de dados são um problema, desfazê-los pode ser um desafio. Depois de ter uma cultura arraigada de separação de dados, é um desafio mudar a mentalidade dos funcionários. Além disso, pode ser difícil desfazer alguns dos silos devido à maneira como os sistemas são configurados com várias permissões e hierarquias. Por exemplo, as permissões são frequentemente configuradas por grupo, portanto, uma vez que os dados são isolados para um grupo, é difícil alterar todas as permissões necessárias. E se os dados estiverem em silos em sistemas diferentes (por exemplo, os dados do grupo Security Operations são armazenados em um banco de dados Oracle, mas as informações de vendas estão no Salesforce), é ainda mais difícil reconciliar os silos.
Para simplificar esse processo, a maioria das empresas move os seus dados dos seus vários sistemas para um data warehouse. Um data warehouse é um repositório para todos os dados coletados pelos sistemas operacionais de uma empresa. Eles são otimizados para acesso e análise, em vez de processamento transacional, e são projetados para ajudar o gerenciamento a obter uma visão 360º dos dados da sua empresa.

Maneiras de quebrar silos de dados
A melhor maneira de remover silos de dados é consolidar os seus dados num data warehouse. Aqui estão alguns métodos diferentes que uma empresa pode usar para inserir dados em um data warehouse:
- Scripting: Algumas empresas usam scripts (escritos em SQL ou Python, etc.) para escrever o código para extrair os dados e movê-los para um local central. No entanto, isso pode ser demorado e também requer uma grande quantidade de experiência.
- Ferramentas ETL locais: As ferramentas ETL (Extrair, Transformar, Carregar) podem aliviar muito a dor de mover os dados, automatizando o processo. Eles extraem os dados de sua origem, realizam transformações e carregam os dados no data warehouse de destino.
- Ferramentas ETL baseadas em nuvem: Essas ferramentas ETL são hospedadas na nuvem, onde pode aproveitar a experiência e a infraestrutura do fornecedor. Eles são comumente usados quando uma empresa decide mover dados em silos para um data warehouse na nuvem. No caso do Power BI, conseguimos fazer isso através dos DataFlows, que nada mais é do que realizar o processo de ETL do Power Query já na nuvem.
Dataflows do Power BI: características
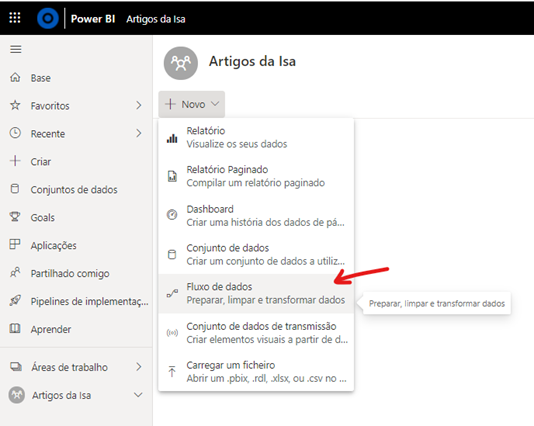
Para simplificar a nossa vida, no bom e velho português, dataflows ou fluxo de dados, é o nosso querido Power Query já em cloud, na nuvem. Ou seja, é o Power Query online, que fica no Power BI Service.
Características:
- Disponível para as licenças PRO, Premium e Premium per user.
- Não está disponível para a ‘My workspace’ ou ‘A minha área de trabalho’. É preciso criar uma área de trabalho para conseguir usar os dataflows. Ou seja, já foi pensado para trabalhar em equipa.

- Permite a conexão com ampla gama de fontes de dados, oferecendo assim, as mesmas facilidades do Power Query do Power BI Desktop.
- Utiliza o poder da nuvem para processamento e salva os dados no Azure Data Lake Storage no formato de arquivos csv.
- No fundo, ele pode servir como um data warehouse, ou uma camada de staging para as empresas que não têm data warehouse.
Dataflows do Power BI: vantagens
- Fornecer uma cópia das tabelas de banco de dados aos analistas de negócios, visto que dificilmente a TI dá acesso diretamente ao banco de dados. Com isso, uma pessoa elencada pela TI pode ficar responsável por criar essas tabelas no dataflows.
- Centralização e reaproveitamento das tabelas resultantes de transformações pelo Power Query, evitando o trabalho de copiar queries de um pbix para outro e ter que manter as mesmas transformações em diferentes locais. Ou seja, criamos todo o processo de limpeza e transformações dos dados na nuvem e depois conseguimos ligar vários arquivos do Power BI Desktop podem consumir essas transformações dos dataflows.
- Programação de diferentes horários e frequências de atualizações de acordo com as tabelas definidas em cada dataflow. Isso é muito bom porque se estivermos a ler dados de diferentes dataflows no nosso relatório do Power BI Desktop, por exemplo, 4 tabelas dataflows diferentes, que vem de diferentes origens, conseguimos agendar cada uma deles com uma frequência desejada.
- Isso é extremamente performático. Enquanto antigamente, agendava a atualização dos dados do relatório para um único horário, dessa forma, agendamos cada dataflow com uma frequência de horário desejada.
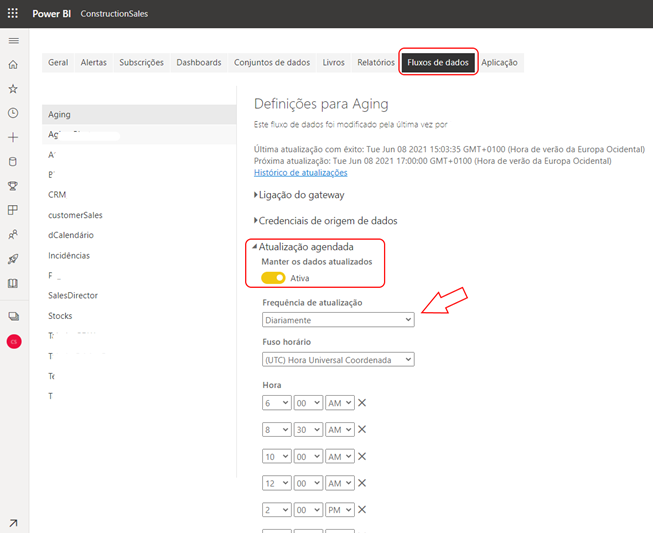
Lembrando que a conta PRO nos dá direito a até 8 atualizações diárias por relatório, enquanto as licenças Premium, esse número aumenta para até 48 atualizações, o que equivaleria a agendar uma atualização a cada 30 minutos.
Digamos que temos um relatório que é composto por duas fontes de dados e em uma delas precisamos atualizar uma vez ao dia e a outra 8x ao dia. Podemos então criar 2 dataflows distintos e programar diferentes horários e frequências de atualizações, acelerando muito o tempo de atualização do conjunto de dados final, que é composto por esses 2 dataflows.
- Os fluxos de dados do Power BI receberam comentários extremamente positivos de clientes e analistas de mercado por causa de sua abordagem inovadora para democratizar a ingestão de dados no data lake de uma empresa para analistas de dados e outros usuários não técnicos.
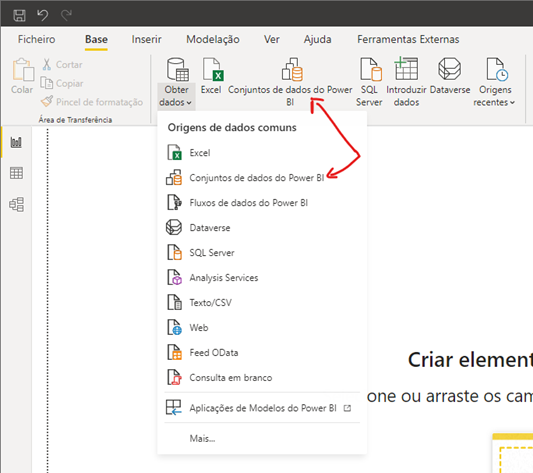
No Power BI, conseguimos aceder aos dados dos dataflow através do friso Base > Obter dados > Fluxo de dados do Power BI.
Ao selecionar essa opção no Power BI Desktop, ele solicitará as credenciais de acesso, para garantir a segurança das informações, e de seguida, selecionará o dataflow desejado que foi criado no Power BI Service.
Recurso extra: Linhagem dos dados
Se por acaso estiver a utilizar utilizar um dataflow com muitas bases de dados, poderá utilizar o recurso de ‘Lineage’, a linhagem do Power BI Service. Ela encontra-se no botão ‘Ver’ > Linhagem. Dessa forma, irá ver uma espécie de histórico dos dados, desde a origem, o dataflow, o dataset, relatório e dashboard, caso o tenha.
Isso facilita muito o entendimento de onde os dados estão a vir, qual a origem de dados, as atualizações…
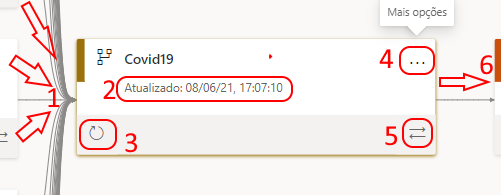
- Essa setas mostram de que origem estão a vir os dados que alimentam esse data flow
- Estamos a ver qual foi a data e horário da última atualização desse dataflow
- Atualizar agora o dataflow
- Mais opções
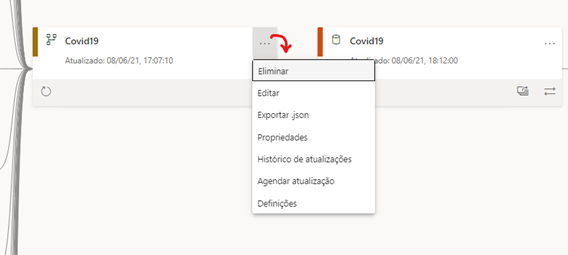
- Mostrar a linhagem, ou seja, o caminho que os dados estão a percorrer desde a origem até o relatório e dashboard
- Seta indica qual o dataset (conjunto de dados) está a alimentar.
Conjuntos de dados partilhados
Sempre que publicamos um arquivo pbix, duas estruturas são criadas no Power BI Service:
- Relatório
- Conjunto de dados
Conjunto de dados é a estrutura que contém os dados transformados, os relacionamentos e as medidas DAX. Ou seja, é o nosso modelo de dados.
Um conjunto de dados em um Workspace pode ser utilizado para a criação de diferentes relatórios. Melhor ainda, é possível publicar esses relatórios em diferentes Workspaces.
Com isso, evita-se a duplicação e manutenção do mesmo modelo, e todo o processo de manutenção e atuação é realizado apenas no Conjunto de dados original.
Portanto, outra forma de lidarmos com o problema dos silos de dados aqui dentro do Power BI é trabalhar com dataset partilhados, ou seja, utilizarmos os conjuntos de dados.
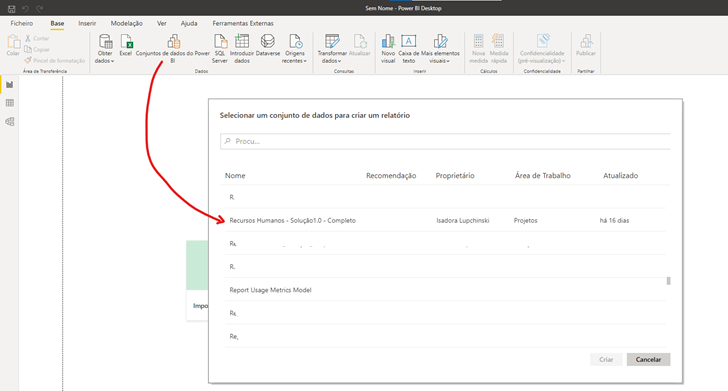
Quando nos conectamos deste jeito, aproveitamos o trabalho feito anteriormente, pois saltamos algumas das principais etapas da construção de um projeto de Power BI. Veja na imagem abaixo qual é o ciclo natural que fazemos:
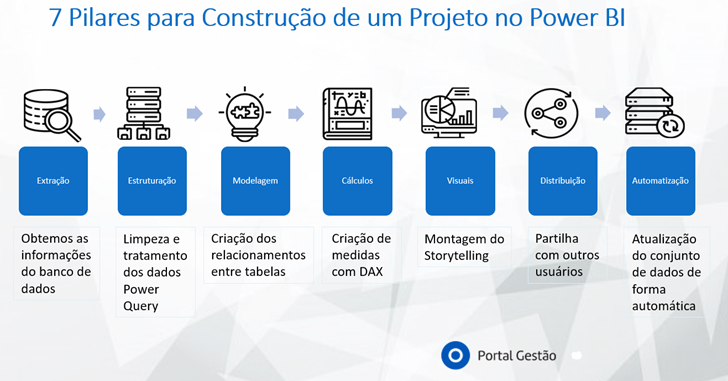
Mas quando obtemos dados de conjuntos de dados no Power BI Desktop, já passamos direto do pilar 1 para o pilar 4 ou mesmo para o 5, o das visualizações.
Dessa forma, se alguém da sua equipa (ou você mesmo) já tiver realizado todo o trabalho de extração da base de dados, limpeza e transformação dos dados (ETL), modelagem e cálculos com DAX, agora, com esse recurso, é partir direto para as visualizações. No entanto, vale lembrar que o modo de conexão que fica é a live, uma conexão direta, em tempo real, com o Power BI Service. Tem algumas desvantagens nisso, como por exemplo, não temos mais o botão de ‘Dados’, ou seja, não conseguimos visualizar esse friso. Bem como não conseguimos editar os relacionamentos.
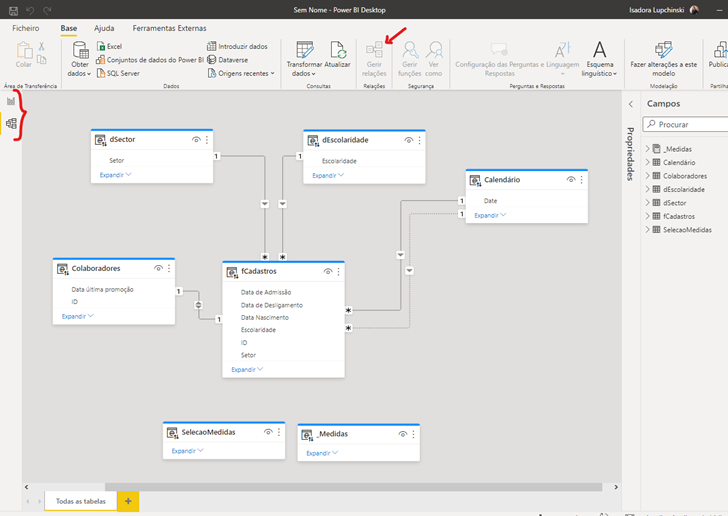
Atenção para o seguinte detalhe: conseguimos criar medidas nesse novo relatório, no entanto, elas serão locais, somente aparecerão nesse relatório. Portanto, se tivermos outros relatórios ligados a esse dataset, essa medida nova que criamos aqui, não será refletida nos demais.
Vamos criar uma medida: Contagem de cargos
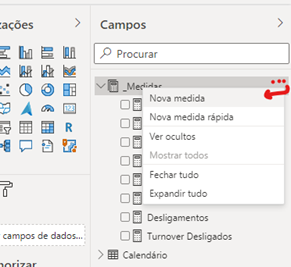
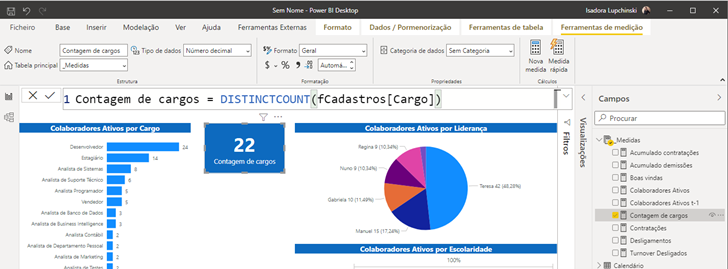
Outro detalhe é que não conseguimos editar as medidas calculadas já existentes, como por exemplo, a colaboradores ativos.
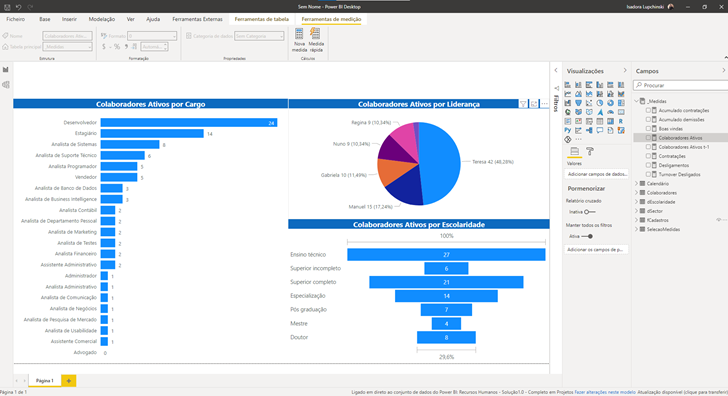
Veja na imagem acima que conseguimos clicar nas medidas do dataset, mas elas não estão editáveis.
Conclusão
Se quisermos manter uma solução com pouca manutenção, altamente escalável, consistente e robusta, então é necessário ter a arquitetura correta e a governança adequada. É preciso unificar e padronizar todo esse trabalho.
Vimos que o Power BI oferece duas funcionalidades muito importante para isso:
- Dataflows (fluxos de dados): em que centralizamos nossas bases de dados e suas transformações (ETL)
- Shared datasets (conjuntos de dados partilhados): em que pegamos um modelo de dados, com os relacionamentos criados, bem como as medidas calculadas (via DAX) e conseguimos criar vários outros relatórios a partir desse único dataset. Ou seja, a centralização fica em um único conjunto de dados.
Espero que tenham gostado desse assunto.
Aproveito para deixar algumas leituras como recomendação, que servem como continuação e complemento do que foi dito aqui hoje.
Espero por vocês no próximo artigo.
Leituras recomendadas
https://docs.microsoft.com/pt-br/power-bi/connect-data/desktop-directquery-datasets-azure-analysis-services
https://docs.microsoft.com/pt-br/power-bi/collaborate-share/service-endorsement-overview
https://docs.microsoft.com/pt-br/power-bi/collaborate-share/service-endorse-content
