
A usar a fórmula RAND para simular variáveis aleatórias
Para simularmos variáveis aleatórias, existe uma pequena fórmula do Excel, a fórmula RAND(), que será a base das simulações Monte Carlo. Esta fórmula, que é anónima porquanto não aceita argumentos, devolve um número aleatório entre 0 e 1. Ao escrevermos a fórmula numa célula do Excel, vamos obter um valor que se altera sempre que a mesma é recalculada. Por isso, dizemos que o seu resultado é volátil.
Experimente introduzir a fórmula RAND numa célula vazia e clicar repetidas vezes na tecla F9. Como verá, o resultado altera-se de cada vez que o faz, porque a tecla F9 força o recálculo de todo o ficheiro Excel, que por sua vez, obriga a fórmula RAND a encontrar novo valor aleatório.
Aparentemente, esta fórmula não tem grande utilidade. Não tem qualquer utilidade, de facto, se utilizada isoladamente. Mas, como base de geração de variáveis aleatórias ela é perfeita.
Voltemos ao exemplo que mostramos no artigo anterior: o que acontece se assumirmos que não sabemos qual vai ser a taxa anual de crescimento das vendas nem qual a margem de contribuição percentual, mas soubermos que situa dentro de valores que nos parecem razoáveis? Será que podemos modelar algo do tipo:
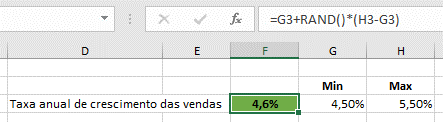
- Taxa anual de crescimento das vendas: entre 4,5% e 5,5%
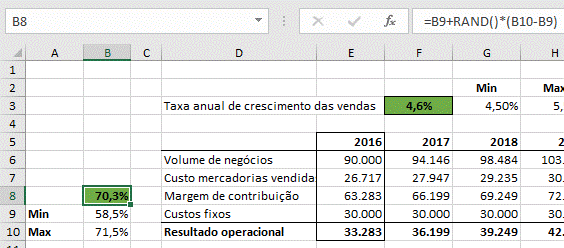
- Margem de contribuição: entre 58,5% e 71,5%
Estamos a assumir que o valor pode ser qualquer um dentro destes intervalos. Para exprimir esta condição numa fórmula do Excel, para cada uma das variáveis, teremos de:
- Encontrar o valor mínimo, que será de 4,5% e 58,5%, respetivamente
- Adicionar esse valor à diferença entre o valor máximo e mínimo, multiplicado por um valor aleatório entre 0 e 1.
Para simular um valor aleatório para a taxa anual de crescimento das vendas, teríamos então a seguinte fórmula:
E para simular a margem de contribuição:
A simulação Monte Carlo
Como estamos a usar valores aleatórios para simular o valor das duas variáveis, de cada vez que recalculamos o ficheiro Excel, as fórmulas produzirão valores diferentes, o que significa que, a cada recálculo, teremos cenários diferentes do plano de negócios a 5 anos.
Ora, a simulação Monte Carlo consiste em gerar 1.000 cenários aleatórios e analisar estatisticamente os resultados do plano de negócios a 5 anos.
Assim, a questão que se coloca agora é: como gerar 1.000 cenários aleatórios de uma forma expedita usando o Excel? Estou a assumir que não é prático clicar 1.000 vezes seguidas na tecla F9 e tomar nota dos resultados…
A solução para este problema pode passar por criar uma tabela de dados, simples, com 1.000 linhas e captar o resultado operacional de 2021 para cada uma delas (há outras soluções para fazer simulações Monte Carlo usando o Excel, nomeadamente a utilização de código VBA e suplementos como o Risk Solver Platform). Vejamos os passos necessários para implementar uma solução deste tipo:
- Começamos por fazer depender as variáveis do modelo de fórmulas RAND, conforme demonstrado acima,
- Criamos uma listagem com números de 1 a 1.000 para cada simulação,
- Criamos uma tabela de dados cujo cálculo corresponde ao resultado de 2021. No fundo, é este o resultado que pretendemos analisar.
Esta tabela é praticamente igual à que demonstrámos anteriormente. Existe apenas um pequeno truque que faz a diferença: uma vez que queremos forçar o Excel a recalcular 1.000 vezes o resultado operacional de 2021 - que depende do resultado volátil da fórmula RAND, vamos “enganá-lo” e ligar o input referente à coluna da tabela a uma célula vazia, por exemplo à célula M1:
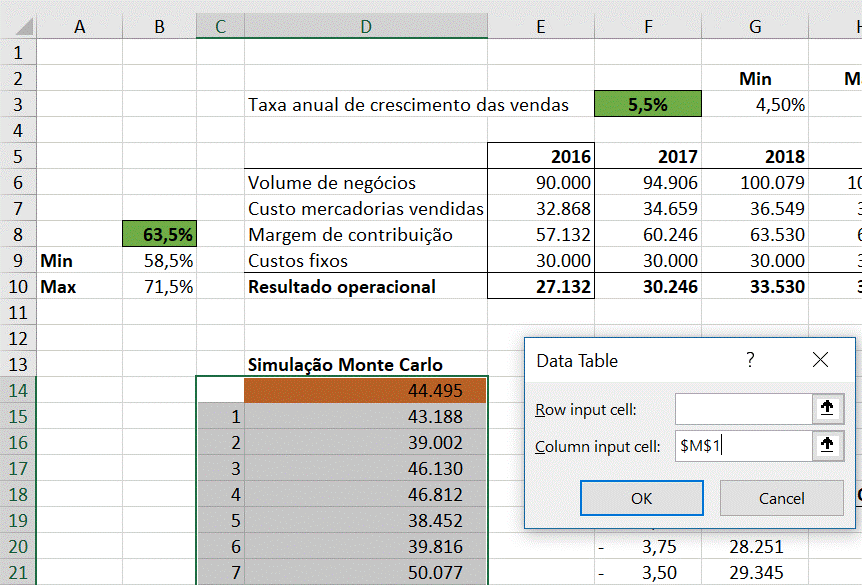
Na célula D14 temos, como esperado, a ligação à célula J10 que contém o resultado operacional de 2021. Deste modo, o resultado da tabela de dados são 1.000 resultados operacionais que correspondem a 1.000 cenários aleatórios para as duas variáveis do nosso modelo.
Chegou a altura de analisarmos estatisticamente os resultados. Mas, para evitar que a cada alteração a cada célula do ficheiro que estamos a usar implique o recálculo da tabela, vamos selecionar a opção do Excel que permite “congelar” os cálculos das tabelas até indicação em contrário. Tal opção pode ser configurada a partir do menu Formulas, Calculation Options e escolhendo a opção “Automatic Except for Data Tables”. Desta forma, a tabela vai manter-se fixa mesmo que realizemos outras operações de cálculo neste ficheiro.
Repare que porque estamos a usar valores aleatórios é muito provável que a sua tabela seja diferente da apresentada neste exemplo, embora as conclusões, como veremos, sejam as mesmas.
O que fizemos até agora? Construímos um modelo com duas variáveis para analisar o resultado operacional de 2021, definimos 1.000 cenários aleatórios para essas variáveis, entre um limite inferior e superior, e criámos uma tabela com os resultados.
Resta-nos agora analisar estatisticamente os resultados. Assim, vamos começar por calcular a média e o desvio-padrão dos 1.000 resultados operacionais de 2021. Para tal, usamos as fórmulas AVERAGE e STDEV.P:
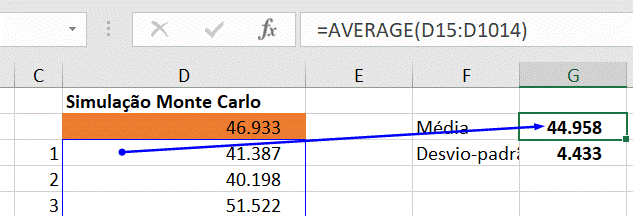
A média das 1.000 simulações indica-nos o valor de €44.958, próximo do valor obtido com o cenário Base, tal como seria de esperar. No entanto, o desvio-padrão é de €4.433, o que representa cerca de 10% do valor da média. Com estes dados, estamos em condições de criar intervalos de confiança que, em vez de nos fornecerem um único número, nos dão informação sobre a probabilidade do resultado operacional se situar dentro de um determinado intervalo de valores.
A distribuição normal
Se o resultado operacional pode assumir valor aleatório contínuo e se conhecemos a sua média e desvio-padrão, podemos aproximá-lo de uma distribuição normal. A distribuição normal tem uma representação em forma de sino e é simétrica, sendo o valor mais elevado o que se situa na média. Quanto mais nos afastamos da média, menor será a densidade de probabilidade.
Por exemplo, se o Quociente de Inteligência (QI) seguir uma distribuição normal com média de 100 e desvio-padrão de 15, qual a probabilidade de um determinado indivíduo escolhido aleatoriamente ter um QI inferior a 90?
Para resolver o problema, vamos recorrer à fórmula NORM.DIST do Excel, que devolve a distribuição normal para uma determinada média e desvio-padrão. No primeiro argumento da fórmula, vamos introduzir o valor 90, ou seja, o valor para o qual queremos obter a distribuição. No segundo, introduzimos a média da distribuição normal (100); no terceiro argumento, o desvio-padrão (15) e, por fim, no último, o valor 1 que indica que pretendemos a função cumulativa (ou seja, todos os valores iguais ou superiores a 90).
A fórmula fica então: NORM.DIST(90;100;15;1), cujo resultado é de 25,2%.
Se pretendermos saber a probabilidade de alguém, escolhido ao acaso, ter um QI superior a 90, então, de acordo com a regra da complementaridade estatística, então teríamos 1-25,2%. Ou seja, a probabilidade seria de 74,8%.
E se por outro lado, alguém se afirma como uma das pessoas mais inteligentes do mundo, cujo QI está no top 2% do mundo? Qual o QI mínimo que deverá ter para não estar a mentir?
A resposta encontra-se na fórmula da distribuição normal inversa, cujo nome é NORM.INV. No primeiro argumento da fórmula teremos 0,98 porque procuramos o QI que está nos 2% à direita da distribuição normal (o percentil 98). No segundo argumento, teremos a média (100) e no terceiro o desvio-padrão (15).
A fórmula exprime-se por: NORM.INV(0,98;100;15) e o resultado é de 130,8.
Depois desta breve explicação sobre a distribuição normal, vamos voltar ao nosso exemplo principal e ver como deixamos de trabalhar com resultados para passarmos a trabalhar com áreas prováveis de resultados.
Especificamente, vamos criar 3 intervalos de confiança:
- Até 1 desvio-padrão em torno da média, que nos dará um intervalo de confiança de 68,3%,
- Até 2 desvios-padrão em torno da média, para um intervalo de confiança de 95,5% e
- Até 3 desvios-padrão em torno da média, para obtermos um intervalo de confiança de 99,7%.
Isto diz-nos que o resultado operacional de 2021 estará entre x e y com um determinado nível de confiança (que nunca será de 100%). Claro que quanto maior o nível de confiança a escolher, mais afastados estaremos da média, ou seja, maior a amplitude de resultados.
Como operacionalizar estes conceitos no Excel? É relativamente simples:
- Começamos por criar uma coluna com um intervalo de desvios-padrão entre -4 e 4 a intervalos de 0,25. Esta amplitude deverá ser mais do que suficiente para abarcar todo o espectro de resultados prováveis,
- Acrescentamos à direita uma coluna com o resultado calculado a partir da média, mais ou menos o número de desvios-padrão que dela se afastam, ou seja, o resultado modelado,
- Acrescentamos mais uma coluna com a contagem do número de ocorrências, das 1.000 simulações, que correspondem a um resultado menor ou igual a esse resultado. Para tal, vamos recorrer à fórmula COUNTIF. Tal valor corresponde à frequência absoluta acumulada,
- Na coluna seguinte acrescentamos o número de ocorrências a cada intervalo de desvios-padrão, a partir da diferença entre o número de ocorrências acumuladas de cada escalão e do escalão imediatamente anterior e
- Por fim, calculamos o valor da densidade de probabilidade de ocorrência de cada resultado calculado na primeira coluna, a partir de uma distribuição normal para a média e desvio-padrão. Para efetuar este cálculo, recorremos à fórmula NORM.DIST, conforme demonstra a seguinte imagem:
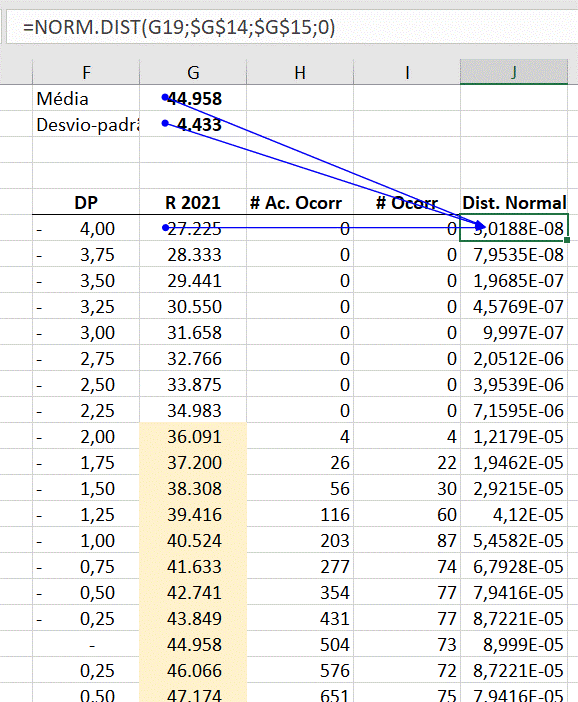
Como já vimos, a fórmula NORM.DIST permite calcular a distribuição normal cumulativa ou a função densidade de probabilidade para uma determinada média e desvio-padrão, consoante o seu último argumento seja 1 ou 0, respetivamente.
A partir da tabela que construímos já podemos ver como o resultado varia em torno da média. De uma forma gráfica será mais fácil analisar esta informação. Vamos construir um gráfico de dispersão com duas séries que mostrem respetivamente:
- No eixo horizontal, o valor do resultado esperado (coluna G),
- No primeiro eixo vertical, o número de ocorrências a cada intervalo (coluna I). Esta será a série 1 que vamos representar através de uma linha laranja,
- No segundo eixo vertical, o valor da função densidade de probabilidade (coluna J). Esta será a série 2 que vamos representar através de uma linha azul.
O resultado final será o seguinte:
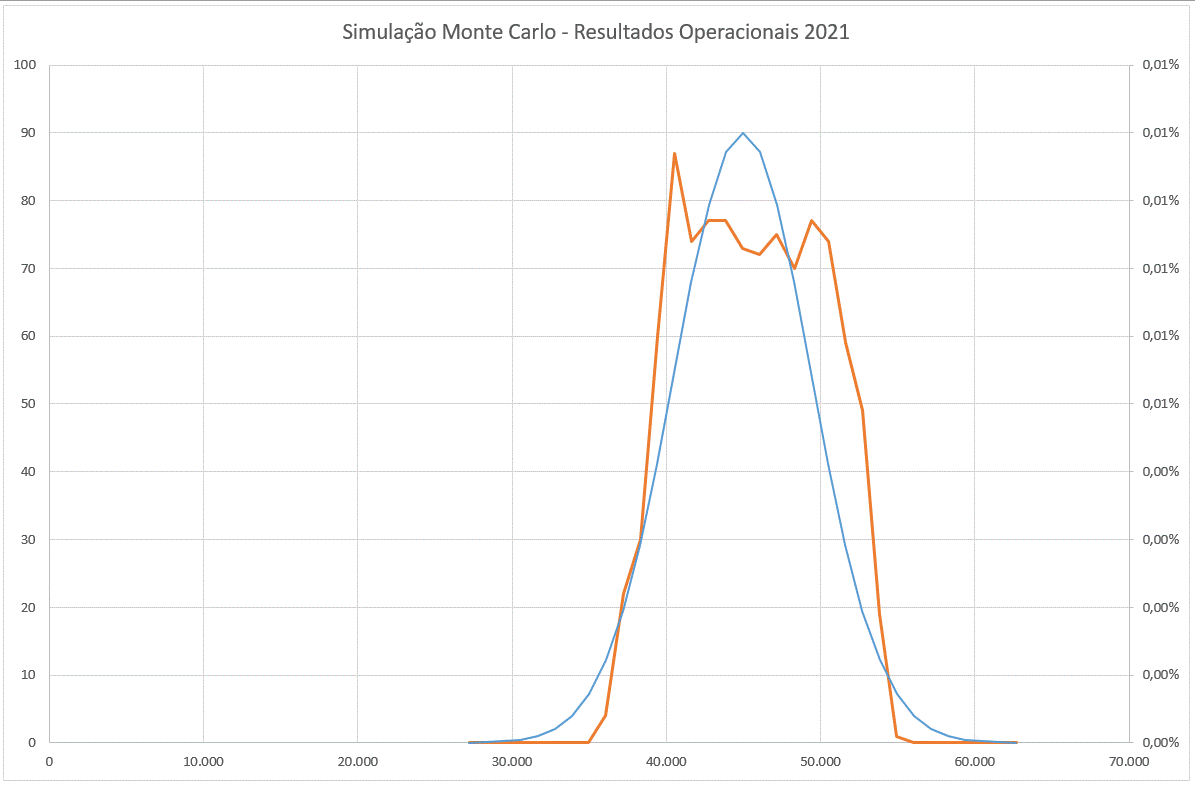
Como vemos, as duas linhas aproximam-se, sendo a linha azul o resultado “teórico” ao qual se aproxima o resultado observado a laranja. O resultado médio situa-se entre €40.000 e €50.000 e é possível observar visualmente que cai abruptamente quanto mais nos afastamos dessa média.
